Machine Learning Movie Recommendations Using AWS Sagemaker


Goal
The goal of this project was to build a Netflix style recommendation engine with AWS SageMaker and other ML tools.
Typically, in any Machine Learning project the Data Preparation phase takes up about 70% of the project time and this proved true for me in this project. For me about 90% of my time was spent in learning ML, learning Jupyter, understanding the IMDb sourced data, cleaning it and preparing it. The remaining 10% was spent on the LAMP (Linux Apache MySQL PHP) setup to deliver the recommendations to the public.
Project Description
Using IMDb Datasets, AWS SageMaker, Jupyter hosted notebook, Python data science libraries and exploring matplotlib, scikit-learn and the k-means learning algorithm I created a Netflix Style Recommendation Engine.
Main Steps
Learning
At the beginning of this project I knew very little about Machine Learning and, thus, I embarked on a step learning curve. In this learning endeavor I used these resources:
A Cloud Guru - Introduction to Machine Learning (6.5-hour course)
A Cloud Guru - Introduction to Jupyter Notebooks (AWS SageMaker) (1-hour hands-on lab)
A Cloud Guru - Introduction to Jupyter Notebooks (3-hour course)
A Cloud Guru - What is Amazon SageMaker (7-minute lesson from AWS Certified Machine Learning – Specialty (LA) Course)


Of course what project can be completed without lots of help from various authors and websites and of course stackoverflow.com
With a foundation of technical knowledge I began the technical work which is broken into five categories.
1. Create Jupyter hosted notebook
To start the data inspection process, I launched a Jupyter hosted notebook on Amazon SageMaker. I used Python and various data science libraries like NumPy and Pandas’ DataFrame to work with the IMBd data.
2. Inspect and visualize data
It was important to gain domain knowledge of the IMDb data so that I could easily detect anomalies and outliers. I used Matplotlib and Seaborn for this step.
3. Prepare and transform data
The next step was to put the data in a format a machine can learn from. The IMDb data includes movies in all languages. The ratings range from 0 to 10 and include the number of votes. For this project I decided to only use English movies and since I want to provide good recommendations I eliminated movies that did not have 500 votes and a rating higher than 7. Since Machine Learning algorithms like numerical data I need to remove or convert all textual information. For the genre information, I converted it into One Hot Encoding (OHE) and then removed the genre column. For the movie title I concatenated it with the index and then removed the movie title column. You can see all of this data transformation and feature engineering in my Jupyter Notebook file found at my github repository
4. Train
Once the data was prepared, the training process began using the selected machine learning algorithm. The algorithm clustered or grouped the IMDb data in order to make recommendations. The plan was to use the k-means clustering algorithm. I considered using two providers: Amazon SageMaker provides a k-means clustering algorithm and so does scikit-learn. I was successful with Amazon SageMaker and so I did not explore scikit-learn's version. I encountered on SageMaker issue that took me several days to resolve. When I first tried to train I got a "413 Request Entity Too Large error" when calling the kmeans predictor predict method. It turns out that when you call the "kmeans_predictor.predict", it means you will invoke the sagemaker endpoint to process the prediction and in the AWS documentation you can find "Maximum payload size for endpoint invocation is 6 MB. Therefore, I split the training data in two parts and invoked the endpoint twice to get two predictions, then I combine two results into one in order to fit the original format.
5. Recommend
With clusters identified and labelled in the Pandas Dataframe (see Jupyter Notebook) I was able to export the CSV to a MySQL database and with some simple PHP and SQL queries I created a basic webpage that provides movies recommendations. This movie recommendation webpage can be found at Brian's Movie Recommendation Site. I will leave this site up for a few days.
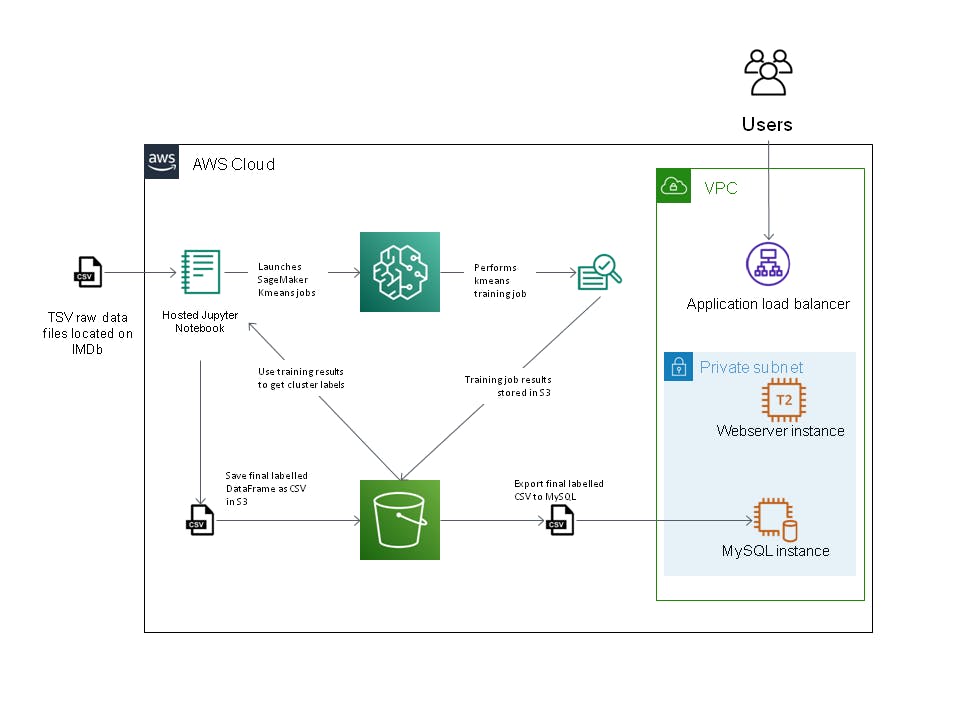
Implemented Architecture
The diagram below depicts the architecture I implemented. Just to be clear all the Machine Learning elements (Jupyter Notebook, SageMaker, etc) to the left of the VPC took up about 90% of the work. The VPC, webserver, database server was created by a CloudFormation template.
Conclusion
This was a very challenging project, but I learned a lot. I am far from being a Machine Learning expert, but neither am I a novice any longer. My interest has certainly been kindled in something which I formerly had very little interest. What I produced works, but it certainly could be refined. I am not completely satisfied with the recommendations that are produced and would like to improve on that.